用JavaScript爬取豆瓣电影TOP250
突然之间看到了一个网站,源代码是用JavaScript实现爬虫相关的功能,瞬间打开新世界的大门。稍加研究,准备用JavaScript制作爬虫练练手,爬取豆瓣榜单TOP250。
这里就不得不提一下,豆瓣榜单TOP250真是初学爬虫非常好的练手项目之一,非常简单,而且也不会有反爬措施,一爬一个准,如果爬不动,只能说是姿势不对,翻翻百度涨涨知识,回头再战。
随着现代网络技术的飞速发展,网络上有非常多的有用的数据,如果单单靠人工去收集这些数据,效率低下不说,而且工作重复性非常高,这时爬虫就是不二的选择。
准备
由于运行环境是Node,所以需要先进行安装。
- axiso
- cheerio
- xlsx(sheetjs)
爬取的网址
https://movie.douban.com/top250
开始
首先需要创建一个Nodejs项目,打开cmd使用命令npm init进行初始化,初始化完毕后需要导入上面的3个库。
npm install axios cheerio xlsx --savecheerio相当于一个精简的jQuery,几乎实现了所有的jQuery的API,同时对DOM的操作更加快速与强大。
https://github.com/cheeriojs/cheerio
axios是一个基于Promise的HTTP 库,可以用在浏览器和node.js中。也可以使用更好上手的request 。
https://github.com/axios/axios
代码很简单
const cheerio = require("cheerio");
const axios = require("axios");
for (let i = 0; i <= 250; i += 25) {
axios.get(`https://movie.douban.com/top250?start=${i}&filter=`).then((response) => {
let $ = cheerio.load(response.data);
$(".info").each((index, f) => {
console.log("标题:" + $(f).find(".title").text());
console.log("评分:" + $(f).find(".rating_num").text());
console.log("简介:" + $(f).find(".inq").text());
});
});
}调用axios.get方法会返回一个Promise,所以我们可以直接通过.then获取返回的数据。
这里主要说一下选择器的思路。
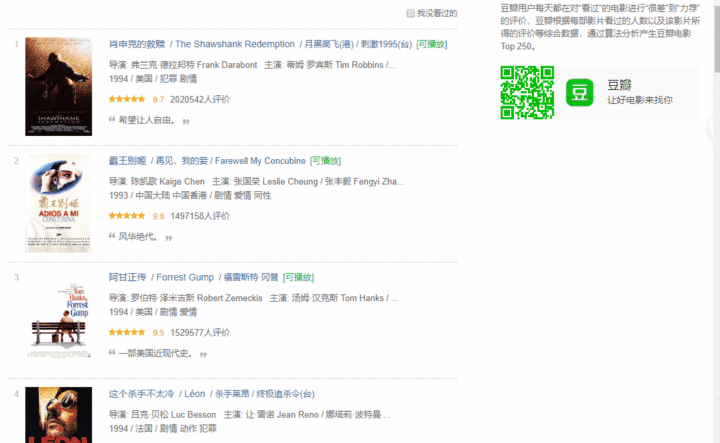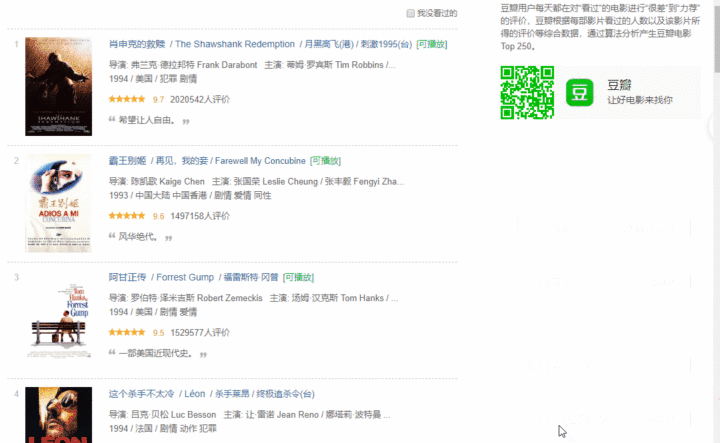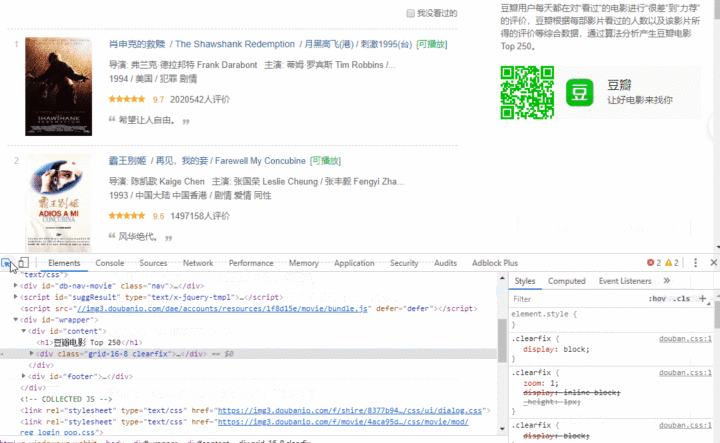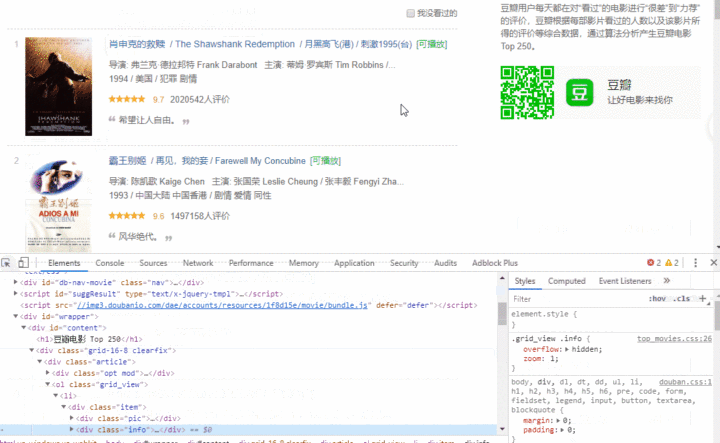
直接通过浏览器的检索功能,找到含有文字内容的容器。
可以看到这个容器有一个类info ,我们可以单单选择这个类,然后输出一下试试
const cheerio = require("cheerio");
const axios = require("axios");
axios.get(`https://movie.douban.com/top250`).then((response) => {
let $ = cheerio.load(response.data);
console.log($(".info").text());
}); 输出结果太长,仅仅贴了一部分
输出结果太长,仅仅贴了一部分
往下翻了翻确定就是需要爬取的内容,然后完善代码:
const cheerio = require("cheerio");
const axios = require("axios");
axios.get(`https://movie.douban.com/top250`).then((response) => {
let $ = cheerio.load(response.data);
$(".info").each((index, f) => {
console.log("标题:" + $(f).find(".title").text());
console.log("评分:" + $(f).find(".rating_num").text());
console.log("简介:" + $(f).find(".inq").text());
});
});到这里,第一页的内容已经全部提取出来了,那么后面的内容怎么办呢,这时我们进到这个网站翻到第二页看看。
可以看到第二页的地址是:https://movie.douban.com/top250?start=25&filter=
第三页的地址是: https://movie.douban.com/top250?start=50&filter=
那么测试一下第一页的地址https://movie.douban.com/top250?start=0&filter= ,测试结果发现能够正常打开首页。
这里就可以得出结论,后一页的地址仅仅改变前一页地址中的start= 后面的数字,并且比前一页多25。
那么到这里就可以写出完整代码:
const cheerio = require("cheerio");
const axios = require("axios");
for (let i = 0; i <= 250; i += 25) {
axios.get(`https://movie.douban.com/top250?start=${i}&filter=`).then((response) => {
let $ = cheerio.load(response.data);
$(".info").each((index, f) => {
console.log("标题:" + $(f).find(".title").text());
console.log("评分:" + $(f).find(".rating_num").text());
console.log("简介:" + $(f).find(".inq").text());
});
});
}运行上面的代码,就可以将豆瓣TOP250的标题,评分,以及简介爬下来,但是现在问题来了,这种爬虫爬下来的数据既无法保存,也不方便查看,那么爬下来的意义又在哪里?如果能够将它保存为Excel,并且通过Excel打开就好了。
保存为Excel
上面的代码仅仅是爬取了数据,但是并没有将它导出为Excel,这个时候一个强大的库sheetjs就上场了。
sheetjs能够将获取的数据通过Excel的形式导出。
https://github.com/SheetJS/sheetjsgithub.com
但是sheetjs只能处理二维数组,所以我们需要将上面爬虫爬到的数据保存为二维数组的形式,再将它用sheetjs存储起来。
我们直接将上面的代码修改一下:
const cheerio = require("cheerio");
const axios = require("axios");
const xlsx = require("xlsx");
async function main() {
let arr = [];
arr[0] = ["标题", "评分", "评论"]; // 表格的第一行
for (let i = 0; i <= 250; i += 25) {
let response = await axios.get(`https://movie.douban.com/top250?start=${i}&filter=`);
let $ = cheerio.load(response.data);
$(".info").each((index, f) => {
// 从第二行开始写入
arr[index + i + 1] = [];
arr[index + i + 1][0] = $(f).find(".title").text();
arr[index + i + 1][1] = $(f).find(".rating_num").text();
arr[index + i + 1][2] = $(f).find(".inq").text();
});
}
let filename = "top250.xlsx"; // 导出表格名称
let ws_name = "Sheet1"; // Excel第一个sheet的名称
let wb = xlsx.utils.book_new(), ws = xlsx.utils.aoa_to_sheet(arr);
xlsx.utils.book_append_sheet(wb, ws, ws_name); // 将数据添加到工作薄
xlsx.writeFile(wb, filename); // 导出Excel
}
main();// 运行函数这里直接引入了async,await,简单的讲就是因为axiso获取页面内容为异步获取,如果使用Promise的.then的方式调用也是可以的,但是不如直接使用async,await简洁明了。
运行上面的代码后会在当前文件夹下面生成一个top250.xlsx文件,打开就可以看到我们爬取的数据。

在网页上面展示
经过测试,爬虫代码直接在浏览器上面跑会出现跨域问题,没有太好的方法解决,不过可以用Nodejs搭建后端,爬虫在后端爬取数据后返回前端。
总结
其实我对于爬虫来说也是一个小白,如果说用Python爬取数据和JavaScript爬取数据有什么特别大的区别,我觉得在爬取数据量不是特别大的情况下,想用哪个用哪个,如果是需要大量爬取数据,还是推荐Python。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!